Quick Overview of Entity Resolution
This blog provides a nice overview of an ACM deep dive into the topic, but for the purposes of this post, I’ll simplify the problem into 3 key steps:
- Feature Engineering — cleaning existing fields and creating new fields for the purposes of comparisons between records (e.g. splitting out first and last name from a single name field)
- Blocking — making a pairwise comparison between every single record can be too computationally expensive, so you need some way to reduce the number of records that you will compare to the query record (e.g. only select records where the last name is an exact match to your query record)
- Matching — actually determining whether or not two records are the same (e.g. this person’s zip code, last name, and age match, so they are the same person)
What Makes this Hard?
I’ve worked with healthcare data for a long-time now, and one of the core challenges I’ve seen is determining whether or not the patient from a claims dataset is the same as the patient in a different clinical dataset. Each time we solved the problem a little differently due to the differences and quirks of every dataset. This means we wrote custom feature engineering, blocking, and matching code each time, and the maintenance burden was quite high as new quirks in the data were discovered all the time (e.g. misspelled names, impossible dates, etc.). While solving (or at least roughly solving depending on the dataset) any individual entity resolution problem is possible, the amount of required engineering time can be prohibitively expensive.
Simplify the Problem with LLMs
LLMs enable us to solve the problem in a much simpler / standardized way:

- Feature Engineering — convert the entire raw record into a small markdown document and then embed that entire document. I’ve mostly used the text-embedding-ada-002 model from OpenAI, but some experiments with other embedding models like https://huggingface.co/thenlper/gte-base show similar / better performance
- Blocking — use cosine similarity to find the top N most similar records. This is not foolproof if the correct match does not appear in the top N records, but empirically this only happens a small % of the time
- Matching — prompt the LLM to pick the correct match from the top N records. GPT-4 appears to be markedly better than GPT-3.5 Turbo at this task, even with few-shot examples, but I haven’t experimented with fine-tuning yet
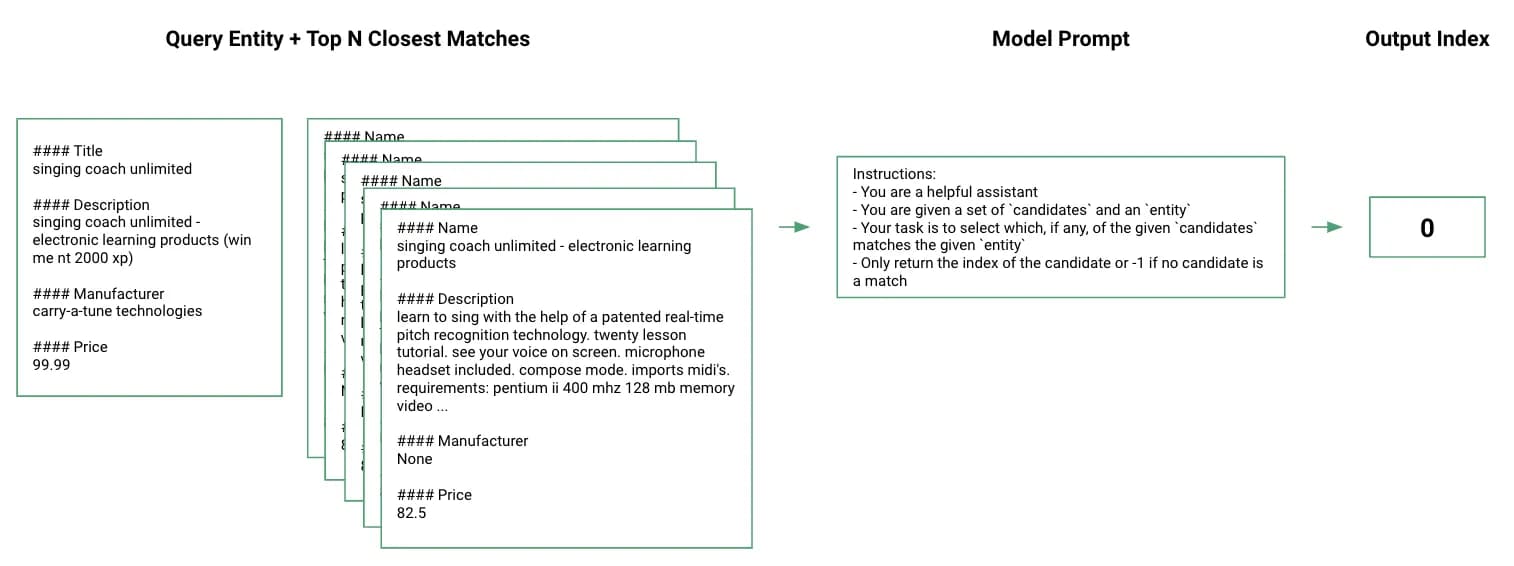
At certain scales of data this approach can become prohibitively slow / expensive relative to other approaches given the current state of LLMs. As these models get cheaper / faster though, these tradeoffs will decrease.